线程池
总体来说,线程池有如下的优势:
(1)降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
(2)提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3)提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的真正实现类是 ThreadPoolExecutor,一般来说创建线程池的方式是直接new出ThredPoolExecutor类对象,调用其构造方法创建池对象
需要如下几个参数:
1 | corePoolSize(必需):核心线程数。默认情况下,核心线程会一直存活,但是当将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。 |
Executors功能性线程池
提供的API有四种:
- 定长线程池(FixedThreadPool)
- 定时线程池(ScheduledThreadPool )
- 可缓存线程池(CachedThreadPool)(可缓存的线程池最常用,但是实际应用中不推荐,推荐直接ThreadPoolExtcutor,不然即使缓存,不进行自定义内存限制,线程数最大创建仍没有限制,可能超出物理内存)
- 单线程化线程池(SingleThreadExecutor)
考虑到ThreadPoolExecutor的构造函数实在是有些复杂,所以Java并发包里提供了一个线程池的静态工厂类Executors,利用Executors你可以快速创建线程池。
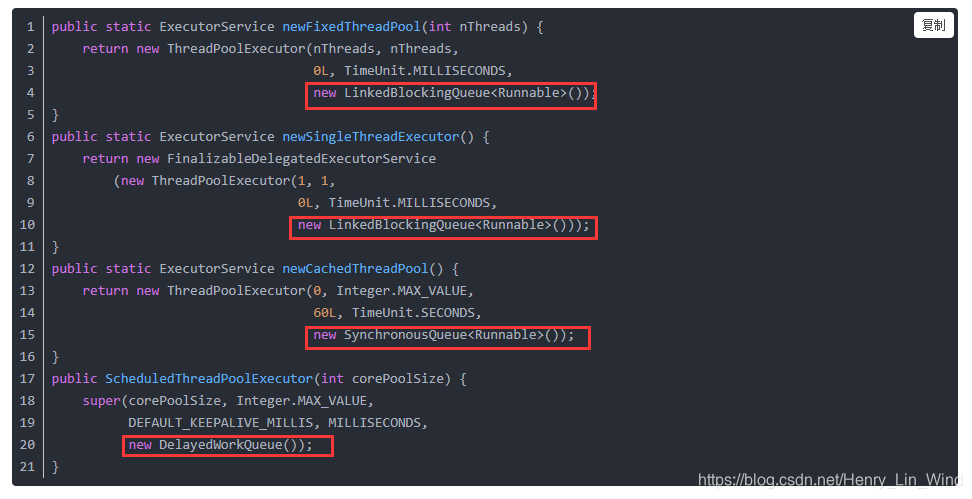
这是一个类,但不建议使用该类,不建议使用Executors的最重要的原因是:Executors提供的很多方法默认使用的都是无界的LinkedBlockingQueue(如下图),高负载情境下,无界队列很容易导致OOM,而OOM会导致所有请求都无法处理,这是致命问题。所以强烈建议使用有界队列。
注:LinkedBlockingQueue是有界队列,但是不设置大小的话,就默认为Integer.MAX_VALUE,相当于无界队列了。
正常线程池的创建和关闭流程
1 | // 创建线程池 |
注意execute执行方法的参数是线程对象,通过创建实现Runnable接口的匿名内部类作为对象参数(run方法重写)
多线程与锁
java线程的级别是内核级的,其实详细的说是用户-内核级的,是由内核线程直接调度用户线程,在jdk1.1时,内核线程指将资源分配给主线程,然后用户线程进行调用,之后就修改了资源分配的机制
修改的原因是每一个线程从底层都是一个函数,都会有一个函数入口,所以需要有独立的一部分空间存储线程私有数据,所以一个函数的栈是不共享的,而堆和代码区和数据区是共享的(在JVM里才是方法区),进程是操作系统分配资源的最小单位
CAS是乐观锁,有三个参数,(地址参数,旧值,新值),可以保证线程修改完,下一个线程修改时如果当前内存的旧值和自己的旧值不相同,就会拒绝当前线程,线程重新进行执行,相当于一个while循环,循环参数为cas,但是可能会产生ABA问题
set和get是一条语句,是一个原子的操作,但是自增不是原子的,自增包含了三个原子操作
锁升级:一个线程获取了锁,对象上markword上标记上线程id,如果出现竞争,升级为轻量级锁,如果自旋失败,升级为重量级锁,这里指的是锁的状态,自旋指的是锁的类型
synchronized的本质是monitor,调用内核的资源,monitor可以执行两个操作monitorenter(monitor中的线程数为0,线程进入并将进入数加一,如果不为0则该线程会被阻塞,等待其他线程出monitor)和monitorexit底层指令执行,entryset和waitset的调度,如果线程调用wait就会进入到waitset中
wait/notify方法必须在同步代码块中,因为必须先持有锁才能进行锁的释放,而且容易出现wakeup问题。因为这两个方法本身就不是原子操作
原子操作:
使用AtomicInteger等类可以进行原子操作,源码使用了CAS,CAS是实现自旋锁的基础,而且CAS是无锁操作,减少性能损耗,cas的原子操作性能比线程加一个锁要高
解决ABA问题的类:使用了增加版本的方式AtomicStampedRefernence,在进行比较时增加一个mark版本号的比较
死锁问题:
死锁的主要引发原因是资源上的冲突,不管是资源空间的不足还是资源的循环占用,它是一个抽象的概念,只要满足了四个条件产生的冲突就叫死锁,而不仅仅是说线程还是进程,因为线程死锁也可以说是进程死锁,原因是线程是进程的组成部分。
单进程死锁会发生吗?(操作系统知识)
可以发生,如果一个进程发起了Io请求,然后本身转出了内存,那么IO请求接收到之后去返回进程发现找不到,那么IO请求会进行等待,而进程转回之后,没有接收到IO也会进入等待,所以产生了单进程的死锁,好像也可以理解成单线程
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !